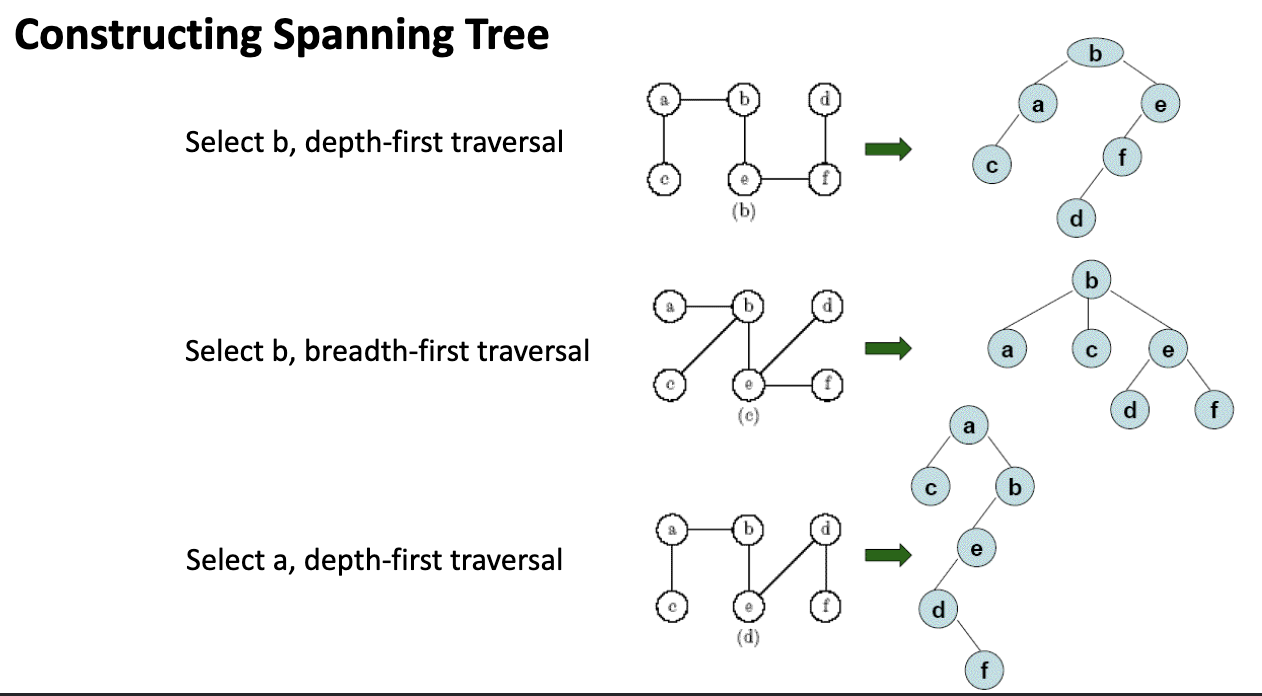
Prim’s algorithm constructs a minimum spanning tree of a weighted, connected, undirected Graph. Start with any single vertex; at each step, add the cheapest edge that connects the existing tree to a vertex not yet in the tree. After steps, you’ve selected edges forming a minimum spanning tree.
A close cousin of Dijkstra’s algorithm — same greedy “expand the cloud” structure, but the priority is “edge weight to a new vertex” instead of “total distance from the source.”
Algorithm
- Pick any starting vertex; mark it as “in the tree.”
- Maintain a set of candidate edges crossing from “in the tree” to “not in the tree.”
- Repeatedly:
- Find the candidate edge with minimum weight.
- Add it (and its non-tree endpoint) to the tree.
- Update candidates: remove edges to the new vertex’s old endpoint (now both ends are in the tree); add edges from the new vertex to its still-out neighbors.
- Stop when edges have been added.
Worked example
For the airport graph, starting from PVD:
Step by step:
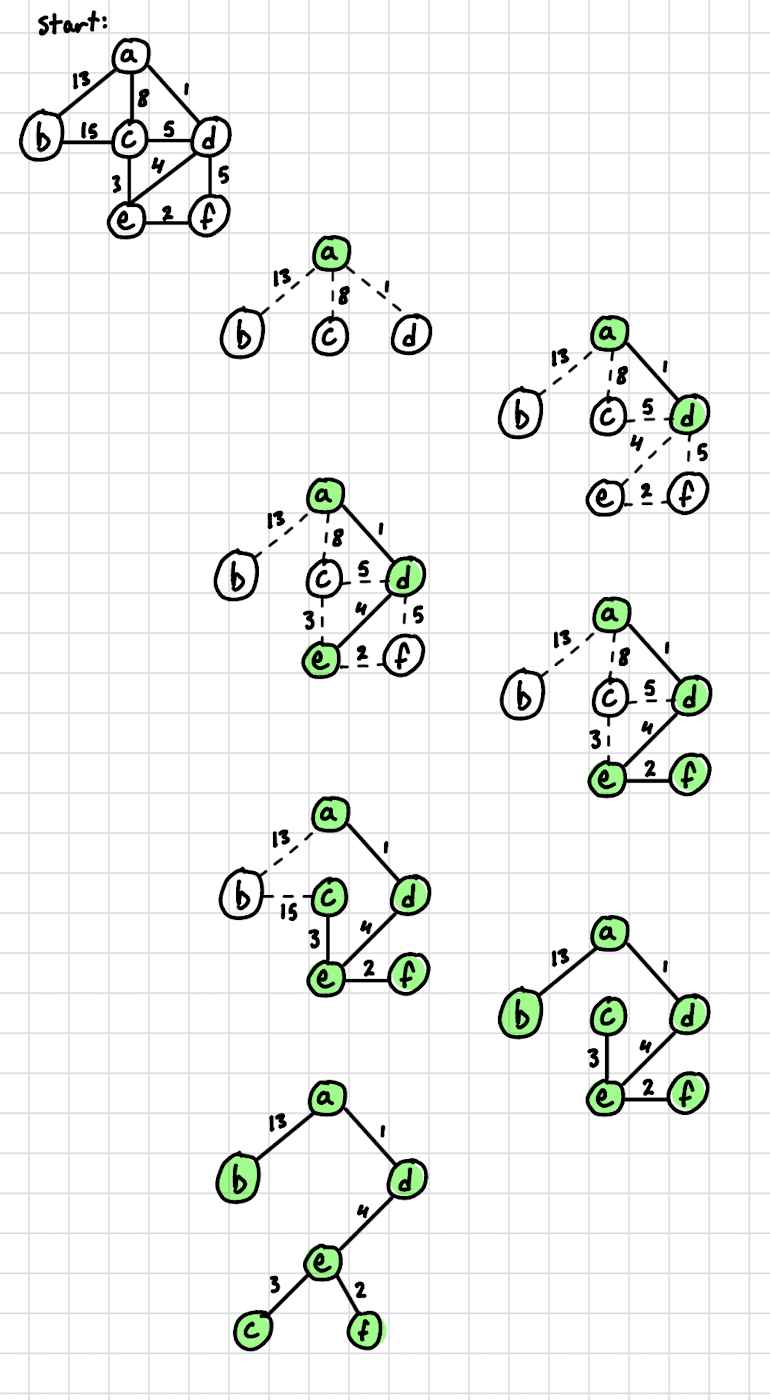
At each step the green vertices are in the tree; the algorithm picks the cheapest edge from a green vertex to a non-green vertex and adds it.
Pseudocode
PRIM(G, start):
for each vertex v: distance[v] = INFINITY
distance[start] = 0
mark all vertices as not-in-tree
for i = 1 to |V|:
pick u = vertex with smallest distance[] not yet in tree
add u to tree
for each neighbor v of u:
if v not in tree and weight(u, v) < distance[v]:
distance[v] = weight(u, v)
predecessor[v] = u
The distance[v] array here means “weight of the cheapest known edge to v from the tree” — different from Dijkstra’s “distance from source.” Otherwise, the structure is the same.
Big O
- Naïve: — for each of iterations, scan all vertices to find the minimum distance.
- With binary heap: .
- With Fibonacci heap: .
For dense graphs, the version is competitive. For sparse graphs, the heap version wins.
Comparison with Dijkstra
Both algorithms maintain a “cloud” of finalized vertices and grow it by greedy choice:
- Dijkstra: minimize — total distance from source.
- Prim: minimize just — single edge weight to z.
So Dijkstra returns shortest paths (lengths from source); Prim returns the cheapest connecting edges (weights to add v to the tree).
For Dijkstra’s “distance to a vertex” perspective, see Dijkstra’s algorithm.
Why Prim works (sketch)
The key claim: at each step, the cheapest edge crossing from “in the tree” to “not in tree” must be in some MST. (Proof: if a different edge were used, you could swap it with the cheapest crossing edge without increasing total weight.)
So greedy edge selection never makes a wrong move — Prim builds toward a valid MST throughout.
Comparison with Kruskal’s
Two classic MST algorithms:
- Prim: grow a single tree from a starting vertex.
- Kruskal: sort all edges, add cheapest if it doesn’t create a cycle (using a union-find structure to detect cycles).
Both are with appropriate data structures. Prim is preferred on dense graphs; Kruskal on sparse graphs.
See also Graph and Dijkstra’s algorithm.