Straight-line sequencing is the default mode of instruction execution: fetch the instruction at PC, execute it, increment PC to point to the next instruction, repeat. Every instruction executes in the order it appears in memory until a branch or jump changes PC explicitly.
For a 32-bit ISA, straight-line means PC increments by 4 per cycle:
PC = i → fetch instruction at i, PC ← i + 4
PC = i + 4 → fetch instruction at i+4, PC ← i + 8
PC = i + 8 → fetch instruction at i+8, PC ← i + 12
...
Each instruction lives at the next word address; instructions are 4 bytes; PC steps in 4-byte chunks.
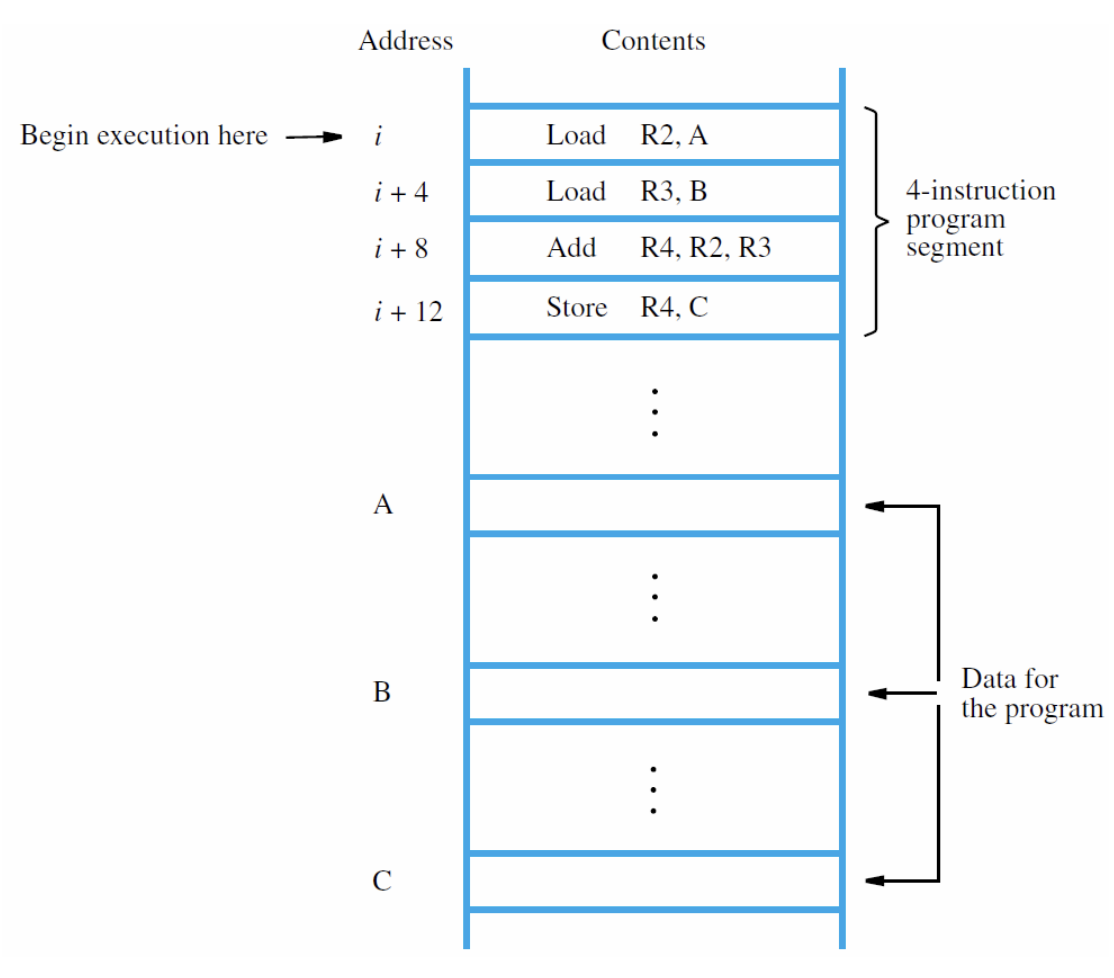
In the diagram: a 4-instruction program sits at consecutive addresses . Data lives elsewhere (at addresses , , ). The processor fetches and executes the four instructions in order.
What breaks straight-line
Three things alter the normal sequence:
- Branch instructions:
beq,bne,bgt, etc. If the branch condition is true, PC ← branch target; otherwise PC continues to PC + 4. - Unconditional jumps:
br LABEL,jmp R5. Always set PC to a new value. - Subroutine calls and returns:
call LABELsaves the return address and jumps;retjumps to the saved return address.
Each of these deviates from straight-line execution. Without them, programs would run from start to end with no loops, conditionals, or function calls, useful only for the simplest sequences.
Why it matters
Straight-line is the predictable case. The processor predicts it implicitly: it can pre-fetch the next instruction at PC + 4 in parallel with executing the current one, because the next address is known immediately.
Branches break this prediction. The branch target may be far from the current PC, and may not even be known until the branch instruction is partly executed. That’s where pipelined processors hit the branch hazard: they have to stall, predict, or speculatively execute to avoid wasting cycles. None of that complexity exists for straight-line code.
The “1 IPC” ceiling belongs to a simple in-order 5-stage RISC pipeline. Desktop and server CPUs today are 4- to 8-wide superscalar with deep out-of-order windows, so on straight-line code with predictable branches and a hot cache they retire several instructions per cycle when the dependency graph allows it. Throughput collapses fast on code with frequent unpredictable branches. Switch-table-heavy interpreters are the textbook example, since the indirect-branch predictor can’t keep up and every misprediction flushes the in-flight pipeline.