Binary search finds a target element in a sorted array by repeatedly halving the search range. At each step, compare the target with the middle element. If they match, done. Otherwise, eliminate the half that can’t contain the target and recurse on the other half.
The algorithm:
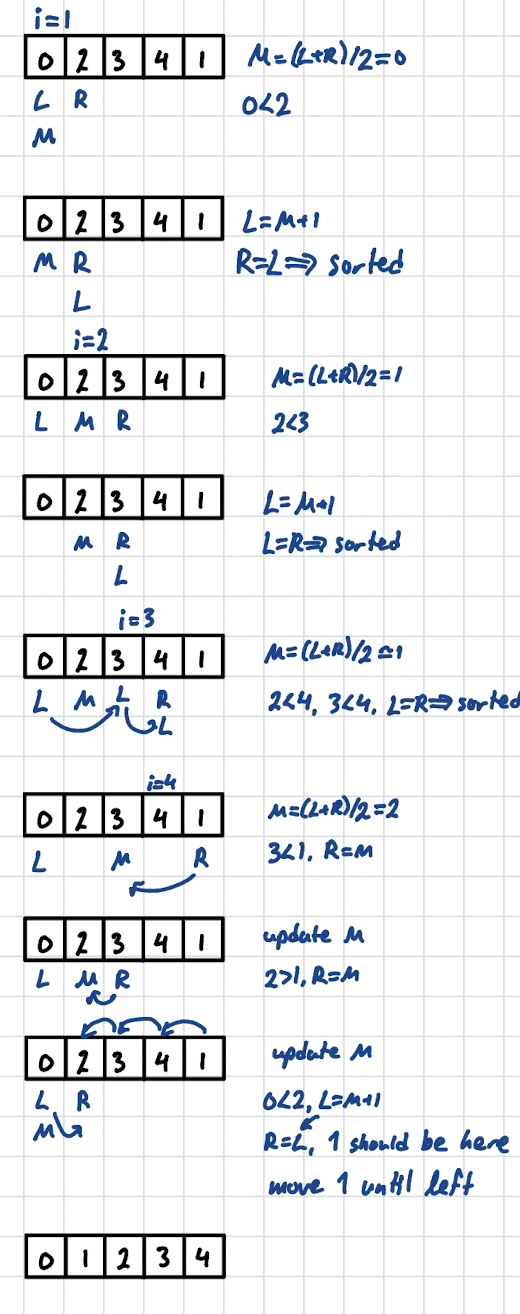
- Compute
mid = (left + right) / 2. - If
arr[mid] == target, found it. - If
target > arr[mid], search the right half:left = mid + 1. - If
target < arr[mid], search the left half:right = mid - 1. - Repeat until found or
left > right(target absent).
int binarySearch(int arr[], int n, int target) {
int left = 0;
int right = n - 1;
while (left <= right) {
int mid = (left + right) / 2;
if (arr[mid] == target) return mid;
else if (arr[mid] < target) left = mid + 1;
else right = mid - 1;
}
return -1; // not found
}
Big O
Each iteration halves the search range. Starting from elements, after iterations the range has size . Set this to 1: .
So binary search is — even for arrays of millions of elements, ~20 iterations max.
This is dramatically better than linear search (): for , binary search needs 20 comparisons; linear search needs up to 1,000,000.
Requirement: sorted input
Binary search only works on sorted data. If the array isn’t sorted, you’d need to sort it first () before searching. For one-off queries, that’s worse than just doing a linear search.
But if you’ll search the same data many times, sorting once and then searching with binary search is much faster than linear search every time. This is why pre-sorted indexes (in databases, in compiled lookups) are everywhere.
Why divide-and-conquer
Binary search is the textbook divide-and-conquer search. Each step divides the problem in half and conquers by recursing on one half (equivalently, narrowing the range). There’s no combine step: the answer from the recursive call is the final answer.
Compare with Merge sort, which divides, conquers recursively, then merges. Binary search’s “merge” step is trivial.
Insertion-sort variant
The PDF’s binary-search example actually combines binary search with insertion sort: for each new element, binary-search the sorted prefix to find its insertion point, then shift elements over to make room. Even though the search is , the shifting is , so the overall sort is still . Binary search just makes it slightly faster than naïve insertion sort.
Why (left + right) / 2 can overflow
A subtle bug in some implementations: if left + right is large, the sum overflows the integer range, even though the average (mid) would fit. The fix:
int mid = left + (right - left) / 2;Mathematically equivalent but avoids overflow. This bug has lurked in real-world code (notably the Java standard library) for years.
Use cases
- Sorted arrays: the canonical case.
- Lookup tables: pre-sorted code tables, log files, spell-check dictionaries.
- Numerical methods: bisection for finding zeros of continuous functions, parameter tuning.
- As a building block: many algorithms use binary search internally —
lower_bound,upper_boundin C++ STL, range queries in databases.
For the alternative on linked structures (where indexed access isn’t , so binary search loses its advantage), use a Binary search tree instead — same logarithmic behavior with a tree structure.