Cache address mapping is how a memory address is split into bit fields the cache uses to look up data. A 32-bit address breaks into three pieces:
[ tag bits | index bits | offset bits ]
- Offset bits: identify a specific byte within a cache block.
- Index bits: pick which cache set (or line) to look in.
- Tag bits: stored alongside cached data; compared against the address’s tag to confirm a hit.
The exact widths depend on the cache configuration: block size, number of sets, and associativity.
Computing the field widths
For a direct-mapped cache:
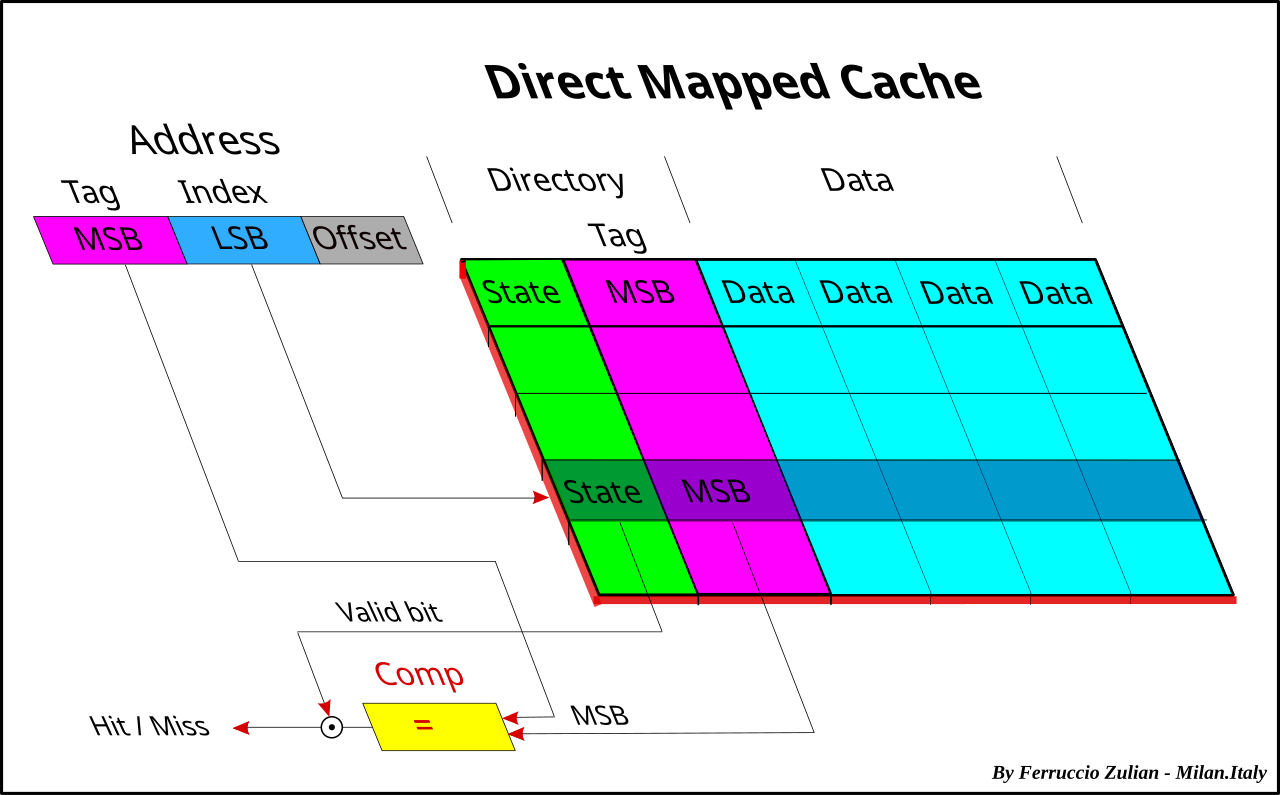 Image: Direct-mapped cache, CC BY-SA 4.0. Each block in main memory has exactly one slot in the cache, selected by the index bits.
Image: Direct-mapped cache, CC BY-SA 4.0. Each block in main memory has exactly one slot in the cache, selected by the index bits.
{kind=link}
For an -way set-associative cache:
- , same.
- .
- , the remainder.
Worked example
Direct-mapped cache, 256 KB total, 8-word blocks (each word 32 bits = 4 bytes), addresses are 32 bits.
Total cache size: bytes.
Block size: bytes per block.
→ Offset bits = 5 (to address each byte in a block).
Number of blocks: .
→ Index bits = 13 (to pick which block).
→ Tag bits = 32 − 13 − 5 = 14.
The address layout:
[ 14-bit tag | 13-bit index | 5-bit offset ]
Mapping a specific address
For address (which is actually in 32 bits):

Binary representation (32 bits):
0000 0010 1110 0001 0111 1011 0110 0000
Splitting from the right:
- Lowest 5 bits (offset):
0 0000→ byte 0 of the block. - Next 13 bits (index):
0 1011 1101 1011→ block index . - Top 14 bits (tag):
00 0000 1011 1000→ tag .
So this address would map to cache block at index , with tag bits . To check for a hit:
- Look up cache slot .
- Compare its stored tag against . If equal, hit.
- Use the offset to get the right byte from the cached block.
If the tag doesn’t match, miss, fetch the new block from main memory.
Direct-mapped vs set-associative
The simplest cache is direct-mapped: each main-memory block has exactly one possible cache slot. Each address’s index bits directly name its slot.
The drawback: two addresses with the same index (but different tags) collide — only one can be cached at a time. If a program alternates between two such addresses, every access misses (“conflict miss”).
Set-associative caches let each index hold multiple blocks. An -way set-associative cache has slots per set; each set is searched in parallel for a tag match. Addresses still map to one set by their index bits, but they can coexist in any of the slots.
| Type | Slots per index | Conflict misses | Hardware cost |
|---|---|---|---|
| Direct-mapped | 1 | High | Low |
| 2-way set-associative | 2 | Lower | More |
| 4-way set-associative | 4 | Lower still | More still |
| Fully associative | All | None (only capacity misses) | Most expensive |
For concrete numbers: Intel’s client Skylake has an 8-way 32 KB L1D (64 sets), a 4-way 256 KB L2 (1024 sets), and a 16-way distributed L3 (1024 sets per slice). AMD Zen 4 runs an 8-way L1D and a 16-way L3. Embedded ARM Cortex cores often sit at 2- or 4-way for L1.
Index bits formula for set-associative
For an -way set-associative cache:
The total number of blocks is the same; you just have blocks per set, which means fewer sets, which means fewer index bits, which means more tag bits to disambiguate.
Worked example: 4-way set-associative cache
Same total cache as before (256 KB total, 32-byte blocks, 32-bit addresses) but now 4-way set-associative.
Total blocks: blocks.
Number of sets: sets.
→ Offset bits = 5 (still 32-byte blocks).
→ Index bits = 11 (to pick one of 2048 sets).
→ Tag bits = 32 − 11 − 5 = 16.
The address layout:
[ 16-bit tag | 11-bit index | 5-bit offset ]
Compared to the direct-mapped version, we lost 2 index bits and gained 2 tag bits. The cache has 4× more entries per set, so 4× fewer sets, so we need 2 fewer bits to name a set.
For the same address :
0000 0010 1110 0001 0111 1011 0110 0000
- Lowest 5 bits (offset):
0 0000→ byte 0. - Next 11 bits (index):
011 1101 1011→ set . - Top 16 bits (tag):
0000 0010 1110 0001→ tag .
To check for a hit:
- Look up set . It has 4 slots.
- Compare each of the 4 stored tags against in parallel. The cache has 4 tag-comparison circuits per set so all four happen at once.
- If any of the 4 matches and its valid bit is set: hit. Use the offset to pull the byte from that slot’s data block.
- If none match: miss. The replacement policy (LRU, pseudo-LRU, random) picks one of the 4 slots to evict.
The win over direct-mapped: any 4 addresses with the same index can coexist in the cache. Conflict misses only happen on the fifth colliding address, not the second.
Fully associative caches
In a fully associative cache, a block can live in any slot. There are no index bits — instead, the address splits into just tag and offset:
[ tag bits | offset bits ]
Lookup compares the address tag against every slot’s tag in parallel using a content-addressable memory (CAM). Hardware cost grows linearly with the number of slots, which is why fully associative caches are practical only for small caches (TLBs, small L1 specialty caches, victim caches).
Conflict misses are zero by construction — any block can go anywhere. The only misses are compulsory and capacity. See the 3C taxonomy for the full picture.
Cache miss rate
The miss rate depends on workload, cache size, and associativity. A simple back-of-the-envelope: for sequential code execution with block size words, the instruction cache miss rate is approximately (one miss per block, then hits as you walk through it).
Real programs have data accesses too, which can dominate. Profiling tools like perf (Linux) report cache misses per instruction so you can see which loops are cache-bound.