The sigmoid function (also called the logistic function) is
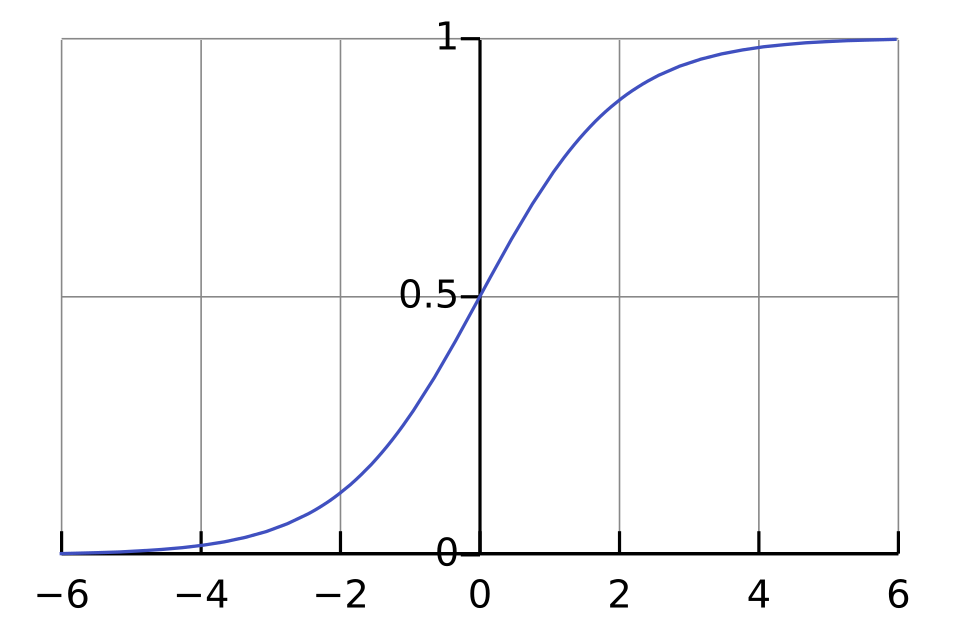 Image: The logistic sigmoid function, public domain
Image: The logistic sigmoid function, public domain
{kind=link}
It maps the entire real line to the interval in an S-shape. The limits:
- As : , so .
- As : , so .
- At : , so .
The shape is nearly flat near 0 for very negative inputs, rises steeply through 0.5 at the origin, and levels off near 1 for very positive inputs.
Why this matters for classification
Because the sigmoid’s output is always in the open interval , we can read it as a probability estimate. If , the model predicts class 1 has probability 0.7 under the model’s assumptions. Whether that estimate is well-calibrated (whether examples the model rates 0.7 actually turn out to be class 1 about 70% of the time) depends on whether the model’s linearity assumption matches the data and on the training procedure. Logistic regression with cross-entropy on well-specified data produces reasonably calibrated probabilities; more flexible models (deep networks, boosted trees) often produce overconfident outputs that need post-hoc calibration. So a sigmoid output is a probability estimate, not literally “the probability.”
The sigmoid takes a linear combination of features that can be any real number:
and squashes it into a valid probability. The S-shape means that small changes in near zero produce big changes in (the model is decisive in the boundary region), while large positive or negative produce nearly constant outputs (the model is confident).
Derivative
The derivative of the sigmoid has a clean form in terms of the sigmoid itself:
This makes the Gradient of logistic regression’s Binary cross-entropy loss very simple: the chain rule produces a clean expression. It’s one reason the sigmoid + cross-entropy combination is the canonical pair for classification.
Alternatives
The sigmoid is one of several activation functions that show up in machine learning:
- tanh — , similar S-shape but maps to instead of . Equivalent to a shifted and scaled sigmoid.
- ReLU — , zero for negative inputs and linear for positive ones. Standard in modern neural networks because it avoids the vanishing gradient problem the sigmoid has for large .
- softmax — generalizes the sigmoid to multi-class classification. For classes, . Produces a probability distribution over the classes.
In binary classification with Logistic regression, the sigmoid is the standard choice. For multi-class problems, softmax replaces it. For hidden layers of neural networks, ReLU dominates in modern practice.