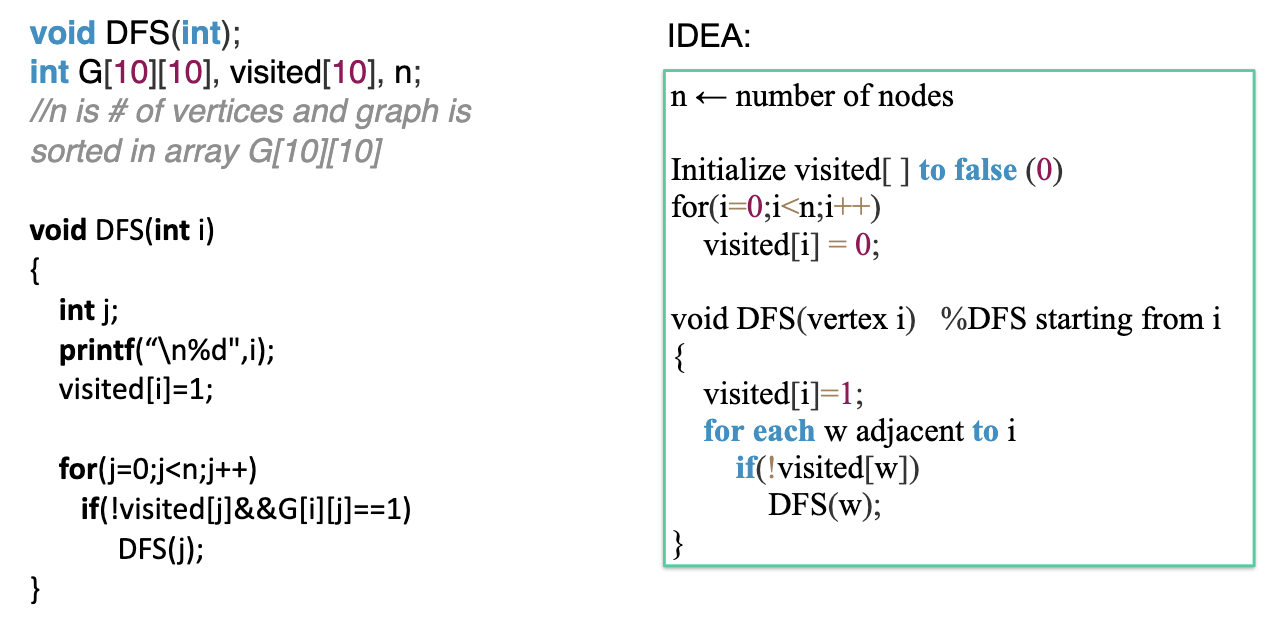
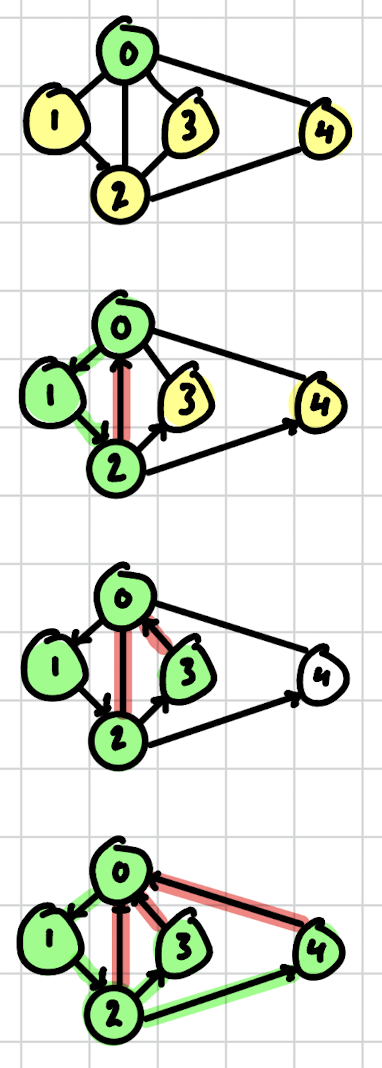
Depth-first search (DFS) explores a Graph by going as deep as possible along each branch before backtracking. From a starting vertex, follow edges to an unvisited neighbor, then from there to an unvisited neighbor, and so on. When you hit a dead end (every neighbor visited), backtrack and try a different path.
Naturally implemented with Recursion (which uses the call stack implicitly) or with an explicit stack data structure.
Algorithm
Recursive form:
void DFS(int v) {
visited[v] = 1;
printf("%d ", v);
for (int u = 0; u < n; u++) {
if (adj[v][u] == 1 && !visited[u]) {
DFS(u);
}
}
}Visit v, mark it. For each unvisited neighbor, recurse. The recursion naturally goes deep into one branch before returning to try others.
Iterative form using an explicit stack:
void DFS(int start) {
push(start);
while (!stackEmpty()) {
int v = pop();
if (!visited[v]) {
visited[v] = 1;
printf("%d ", v);
for (int u = n - 1; u >= 0; u--) {
if (adj[v][u] == 1 && !visited[u]) {
push(u);
}
}
}
}
}
The iterative version uses a stack instead of recursion. Otherwise the same logic.
Why a stack
A stack’s LIFO property gives the depth-first behavior:
- The most recently discovered neighbor is the first to be explored.
- Once you push neighbors of
v, they sit on top of any previously discovered (but not yet visited) vertices. - Popping gives you “the latest unexplored thing” — exactly what depth-first means.
In recursive DFS, the call stack plays this role automatically.
Big O
Same as BFS:
- With adjacency matrix: .
- With adjacency list: .
Each vertex is visited once; the work per vertex is proportional to its degree.
DFS vs BFS
Both visit every reachable vertex once. They differ in order:
| DFS | BFS | |
|---|---|---|
| Data structure | Stack (or recursion) | Queue |
| Order | Deep into one branch first | Level by level |
| Memory | where = max depth | where = max width |
| Shortest path? | No (in unweighted graphs) | Yes (unweighted) |
| Use cases | Backtracking, topo sort, cycle detection | Shortest path, level ordering |
DFS is more memory-efficient for deep narrow graphs (the stack only needs to hold the current path). BFS wins for shallow wide graphs. Pick based on graph shape and what you’re computing.
Use cases
- Connectivity / components: run DFS, count components.
- Cycle detection: in directed graphs, a back edge during DFS indicates a cycle.
- Topological sort: post-order DFS gives a valid topological order for a DAG.
- Maze solving: DFS naturally backtracks when it hits a dead end.
- Strongly connected components (Tarjan’s algorithm, Kosaraju’s algorithm) — both built on DFS.
- Path finding: when “any path” is good enough (not necessarily shortest).
DFS doesn’t guarantee finding the shortest path. If you need shortest paths in an unweighted graph, use Breadth-first search. For weighted shortest paths, Dijkstra’s algorithm.
Behavior: complete vs partial
If the graph is connected, DFS from any vertex reaches every vertex. If not connected, DFS only reaches vertices in the same connected component as the start.
To traverse a disconnected graph, run DFS in a loop: for each unvisited vertex, call DFS. This produces one DFS tree per component.
For BFS as the alternative traversal style, see Breadth-first search.